ChemBench is a cutting-edge framework to evaluate the chemical knowledge and reasoning capabilities of large language models (LLMs). While LLMs excel in general domains, their chemistry expertise remains unexplored. ChemBench fills this gap with 2,700+ curated question-answer pairs across diverse chemistry topics, plus advanced features like visual LLM support, batched inference, and refusal counting. It uniquely encodes chemical semantics, enabling models to process and reason about molecules and equations.
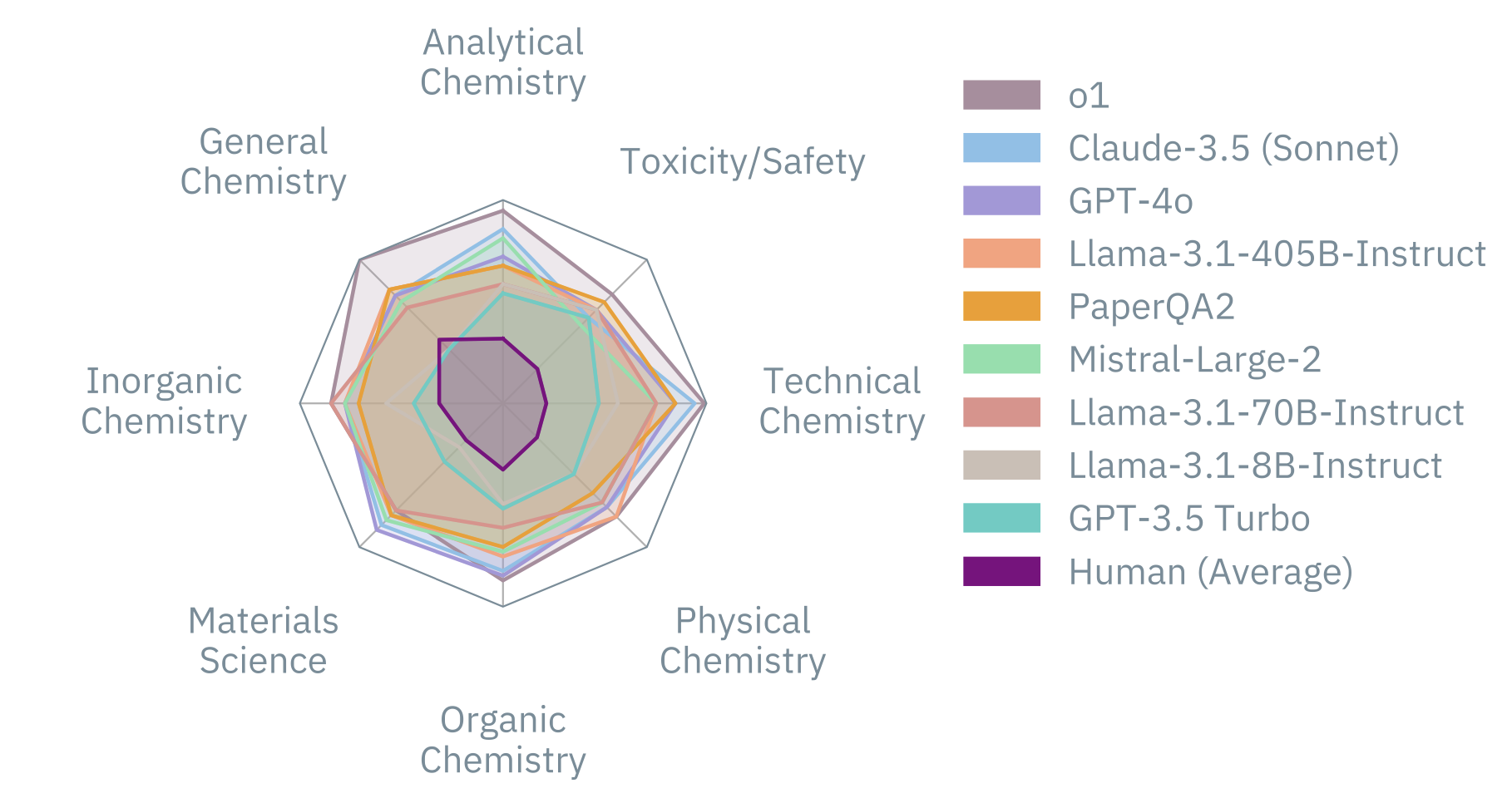
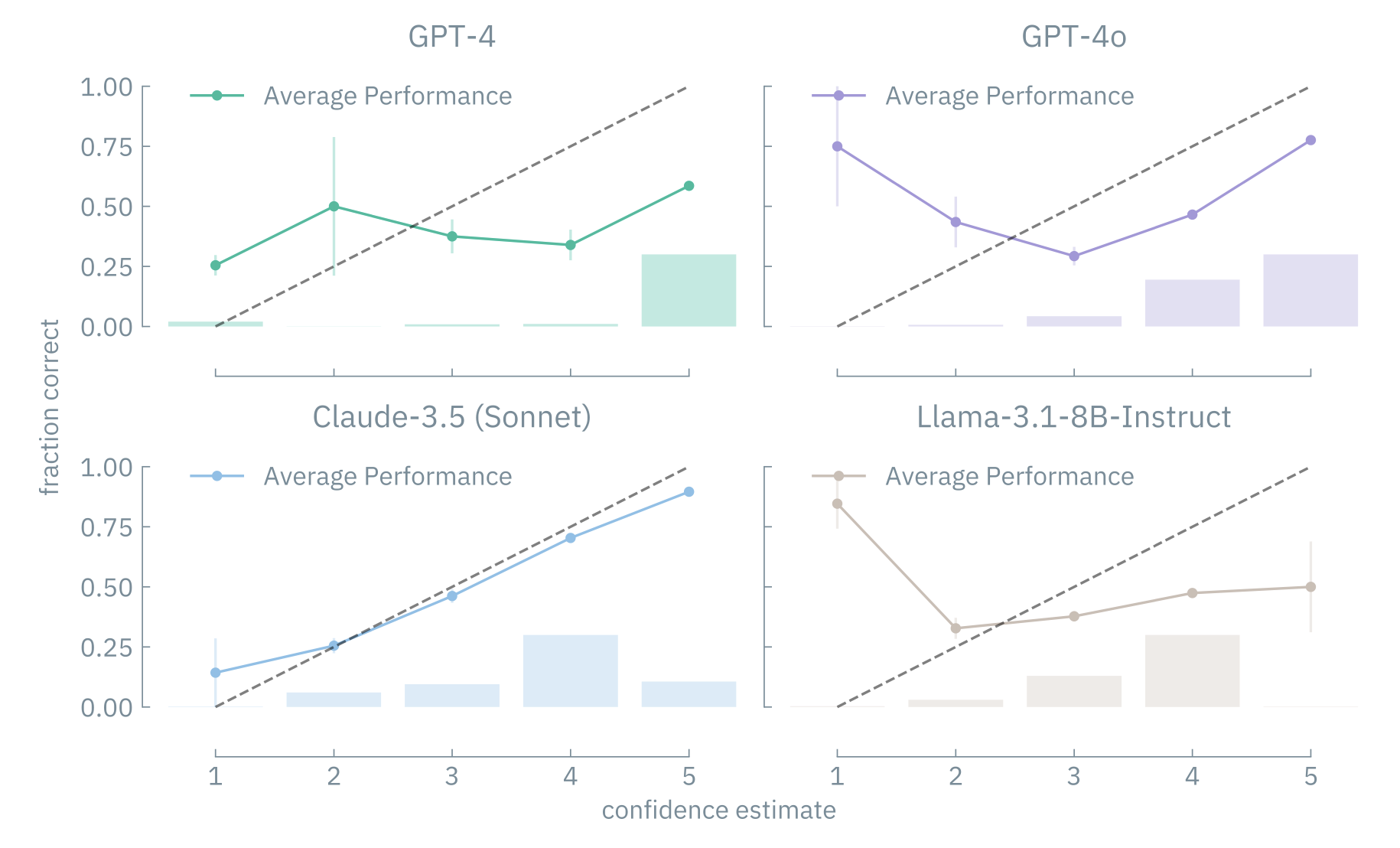
We benchmarked closed- and open-sourced LLMs against human experts and were struck by the results: top models outperformed most humans. Yet, LLMs still struggle with human-aligned preferences, knowledge-intensive questions, and specialized reasoning. These gaps highlight the need for domain-specific training and improved reasoning.
ChemBench not only provides a robust evaluation tool for easy benchmarking, but also illuminates LLMs' strengths and weaknesses in chemistry, paving the way for smarter AI in scientific fields.